تحویل مستمر (Continuous Delivery) چیست؟
تحویل مستمر، توانایی اعمالِ تغییرات (از هر نوعی؛ فیچر جدید، تغییرات تنظیماتی، باگفیکسها و…) در محیط عملیاتی آنهم بصورت امن، سریع و پایدار، میباشد.
هدف ما این است که فرآیندهای دیپلویمنت، چه برای سیستمهای توزیعشدهی بزرگ، محیطهای عملیاتیِ پیچیده، سیستمهای توکار (embedded system) یا اپلیکیشنها، به اموری پیشبینیپذیر و روتین تبدیل شوند که بتوان در هر زمان به سادگی آنها را اجرا کرد.
ما به این هدف درحالتی دست مییابیم که کد ما همیشه در حالت قابل دیپلوی باقی بماند، حتی در شرایطی که هزاران توسعهدهنده روزانه تغییراتی در آن ایجاد میکنند. به این ترتیب، مراحل ادغام، آزمایش و مقاومسازی (hardening) که به طور سنتی پس از تکمیل توسعه انجام میشد، بطور مکرر در حین توسعه انجام میشود.
چرا تحویل مستمر؟
عمدتا اینطور تصور میشود که اگر بخواهیم نرمافزار را به دفعات زیاد دیپلوی کنیم، از سطح پایداری و قابلیت اطمینان سیستمهایمان میکاهیم، اما تحقیقات معتبر و بررسیشده نشان میدهد که این باور صحیح نیست. تیمهای با عملکرد بالا (چندین دیپلوی در روز)، بطور پیوسته سرویسهایشان را سریعتر و با اطمینان بیشتری نسبت به همتاهای با عملکرد ضعیف به دست مشتری میرسانند.
این موضوع حتی در حوزههای بسیار قانونمند مانند سازمانهای مالی و دولتی هم صادق است. در واقع این توانایی (سریعتر و مطمئنتر بودن در تحویل نرمافزار) یک مزیت رقابتی فوقالعاده برای سازمانهاست که حاضرند برای دستیابی به آن تلاش و هزینه کنند.
practiceهایی که در قلب تحویل مستمر هست به ما کمک میکنند تا به چندین مزیت مهم دست یابیم:
- انتشارهای کمریسک (low-risk releases). هدف اصلی تحویل مستمر (CD) این است که فرآیند دیپلوی نرمافزار به رویدادی بدون دردسر (painless) و کمریسک تبدیل شود که در هر زمان و بر اساس نیاز قابل انجام باشد. با استفاده از الگوهایی نظیر بلو-گرین دیپلویمنت میتوان به دیپلویهای بدون وقفه (down time) دست یافت که برای کاربران نهایی غیرقابل تشخیص است.
- زمان سریعتر برای عرضه به بازار (faster time to market). در چرخهی سنتی تحویل نرمافزار، مرحله یکپارچهسازی و رفع اشکال میتواند هفتهها یا حتی ماهها طول بکشد. اما زمانیکه تیمها فرایندهای build و دیپلوی، آمادهسازی محیط و تست رگرسیون را خودکار میکنند، توسعهدهندگان میتوانند یکپارچهسازی (integration) را به کارهای روزانهی خود اضافه کنند و از حجم زیادی از دوبارهکاریهای مرسوم در رویکرد سنتی بپرهیزند.
- کیفیت بالاتر (higher quality). زمانی که توسعهدهندگان ابزارهای خودکاری در اختیار دارند که رگرسیونها را در عرض چند دقیقه شناسایی میکنند، تیمها میتوانند انرژی خود را بر روی تحقیق درباره نیازهای کاربران و فعالیتهای تست در سطوح بالاتر، مانند تست اکتشافی، تست کاربردپذیری، و تست عملکرد و امنیت متمرکز کنند.
- هزینههای کمتر (lower cost). تمام شعار این سایت کاهش هزینههای تولید و نگهداری نرمافزار است. هر محصول یا سرویسِ نرمافزاریِ موفق در طول عمر خود تغییرات قابل توجهی را تجربه خواهد کرد. با سرمایهگذاری در خودکارسازی فرآیندهای build، تست، دیپلوی و آمادهسازی محیط، هزینه اعمال و تحویل تغییرات تدریجی در نرمافزار را به طور چشمگیری کاهش میدهیم، زیرا بسیاری از هزینههای ثابت مرتبط با فرآیند انتشار حذف میشوند.
- محصولات بهتر (better product). تحویل مستمر باعث میشود که ما روی تغییرات کوچک (small batches) کار کنیم. و کار روی small batches باعث میشود که سریعتر از مخاطب بازخورد دریافت کنیم. تکنیکهایی مانند تست A/B به ما این امکان را میدهند که از یک رویکرد مبتنی بر فرضیه در توسعه محصول استفاده کنیم، به طوری که بتوانیم ایدهها را قبل از پیادهسازی کامل ویژگیها با کاربران آزمایش کنیم. این رویکرد به ما کمک میکند تا از ایجاد دو سوم ویژگیهایی که هیچ ارزشی برای کسبوکارها ایجاد نمیکنند، اجتناب کنیم.
- تیمهای شادتر (happier teams). تحقیقات معتبر نشان دادهاند که تحویل مستمر، فرآیندهای انتشار (release process) را کمتر دردناک کرده و خستگی تیم را کاهش میدهد. علاوه بر این، با انتشار مکرر، تیمهای تحویل نرمافزار میتوانند تعامل بیشتری با کاربران داشته باشند، بفهمند کدام ایدهها مؤثر هستند و کدام نیستند، و نتایج کارهای خود را به صورت مستقیم مشاهده کنند. با حذف فعالیتهای کمارزش و دردناکی که با تحویل نرمافزار همراه هستند، میتوانیم بر چیزی که بیشتر برایمان اهمیت دارد تمرکز کنیم: خوشحال کردن مداوم کاربرانمان.
اگرچه تحویل مستمر بسیار جذاب بنظر میرسد، اما توجه داشته باشید که CD جادو نیست. بحث بهبود مداوم و روزانه است. و این در عمل بدست نخواهد آمد مگر با تعهد تیم در بهبود مستمر امورجاری و تکراری.
اصولِ تحویل مستمر
تحویل مستمر بر پنج اصل کلیدی بنا شده است:
۱. بامحوریتِ کیفیت بسازید. (Build quality in)
۲. روی تغییرات کوچک کار کنید. (Work in small batches)
۳. کارهای تکراری را به کامپیوترها بسپارید، انسانها برای حل مشکلات بگذارید.
۴. بهبود مستمر را بیوقفه دنبال کنید.
۵. همه مسئولاند.
گاهی ممکن است در جزئیات پیادهسازیِ تحویلِ مستمر نظیر ابزارها، معماری، رویهها یا مسائلِ سازمانی غرق شوید. چنانچه احساسِ سردرگمی کردید، بازگشت به این اصول میتواند دوباره شما را متمرکز و سرخط کند و همچنین یادآوری کند که چه چیزی واقعا اهمیت دارد.
با محوریتِ کیفیت بسازید
ادواردز دمینگ، یکی از چهرههای کلیدی جنبش لین، در اصل سوم از ۱۴ اصل مدیریتی خود بیان میکند: «برای دستیابی به کیفیت به بازرسی متکی نباشید. نیاز به بازرسیهای گسترده را با محوریت قراردادنِ کیفیت در ابتدا، حذف کنید.»
برطرف کردن مشکلات و عیوب اگر بلافاصله شناسایی شوند بسیار ارزانتر است—در بهترین حالت، قبل از اینکه کد به کنترل نسخه (Version Control) اضافه شود. این کار با اجرای تستهای خودکار لوکالی امکانپذیر است. یافتن عیوب در مراحل بعدی، مانند تستهای دستی، وقتگیر است و نیاز به بررسی و رفع مشکل دارد؛ آن هم زمانی که احتمالاً فراموش کردهایم چه چیزی در ابتدا باعث بروز مشکل شده است. این مفهوم با بنمایهی مفهوم امنیتازابتدا (Shift left security) نیز همخوانی دارد.
ایجاد و بهبود مداوم حلقههای بازخورد برای شناساییِ مشکلات، در سریعترین زمان ممکن، بخشِ حیاتی و بیپایانِ تحویل مستمر است. اگر در تستهای اکتشافی (exploratory) مشکلی پیدا شد، باید نهتنها آن را رفع کنیم، بلکه بپرسیم:
چگونه میتوانستیم این مشکل را با یک تست پذیرش (acceptance) خودکار شناسایی کنیم؟
اگر تست پذیرش شکست خورد، باید پرسید:
آیا میتوانستیم با یک Unit Test این مشکل را شناسایی کنیم؟
روی تغییرات کوچک کار کنید
در روشهای سنتی توسعه نرمافزار، انتقال کارها بین تیمها (مثل توسعه به تست، یا تست به عملیات) معمولاً شامل کُلِ یک نسخه میشود: ماهها کار توسط دهها یا صدها نفر. اما در تحویل مستمر، ما برعکس عمل میکنیم. تلاش میکنیم هر تغییر کوچک را تا حد امکان به سمت انتشار پیش ببریم و بازخورد جامعی را سریع دریافت کنیم. مزایای کار روی تغییرات کوچک عبارتند از: کاهش زمان دریافت بازخورد، سهولت در شناسایی و رفع مشکلات، و افزایش بهرهوری و انگیزه.
دلیل اینکه تمایل داریم روی تغییرات بزرگ کار کنیم، هزینههای ثابت و بالایِ انتقال تغییرات است. این جمله را دوبار بخوانید. یکی از اهدافِ کلیدیِ تحویلِ مستمر این است که اقتصادِ فرایند تحویلِ نرمافزار را تغییر دهد تا کار در مقیاسهای کوچک بهصرفه باشد و از مزایای فراوان آن بهرهمند شویم.
کارهای تکراری را به کامپیوترها بسپارید، انسانها برای حل مشکلات بگذارید.
یکی از مفاهیم فلسفی در سنت تویوتا، جیدوکا (Jidoka) است که گاهی به “اتوماسیون با لمس انسانی” ترجمه میشود. هدف این است که کامپیوترها کارهای ساده و تکراری، مثل تستهای رگرسیون، را انجام دهند و انسانها روی حل مشکلات متمرکز شوند.
بسیاری از افراد نگران هستند که اتوماسیون شغل آنها را تهدید کند. اما این هدف اتوماسیون نیست. در یک شرکت موفق، همیشه کارهایی برای انجام دادن وجود دارد. در عوض، اتوماسیون انسانها را از کارهای یکنواخت آزاد میکند تا بر فعالیتهای ارزشمندتر تمرکز کنند. این موضوع همچنین باعث بهبود کیفیت میشود، زیرا انسانها در انجام کارهای بیهوده بیشترین خطا را دارند.
بهبود مستمر را بیوقفه دنبال کنید
بهبود مستمر یا کایزن (Kaizen) یکی دیگر از مفاهیم کلیدی جنبش لین (lean) است. تایایچی اونو، یکی از شخصیتهای برجسته تاریخ شرکت تویوتا، میگوید:
«فرصتهای کایزن بینهایت هستند. فکر نکنید که با بهبود وضعیت از قبل بهتر شدهاید و راحت باشید… این مانند دانشآموزی است که به خودش افتخار میکند چون دو بار از سه بار استادش را در شمشیرزنی شکست داده است. مهم است که در کارِ روزمره خود این نگرش را داشته باشید که درست زیر یک ایده کایزن، ایده دیگری وجود دارد.»
بهترین سازمانها جایی هستند که همه افراد بهبود را بخشی ضروری از کار روزمره خود میدانند و هیچکس از وضعیت موجود راضی نیست.
همه مسئولاند
در سازمانهای با عملکرد بالا، هیچ چیزی “مشکل کس دیگری” نیست. توسعهدهندگان مسئول کیفیت و پایداری نرمافزاری هستند که میسازند. تیمهای عملیات مسئول کمک به توسعهدهندگان در نهادینه کردن کیفیت هستند. همه با هم برای دستیابی به اهداف سازمانی تلاش میکنند، نه اینکه فقط بخش خود را بهینه کنند.
وقتی افراد بهمنظور بهبود عملکرد شخصی یا تیمی، بهینهسازیهایی انجام میدهند که عملکرد کلی سازمان را کاهش میدهد، معمولاً به دلیل مشکلات سیستمی مانند مدیریت ضعیف یا مشوقهای اشتباه است. به عنوان مثال، پاداش دادن به توسعهدهندگان بر اساس افزایش سرعت کدنویسی یا پاداش دادن به تسترها بر اساس تعداد اشکالاتی که پیدا میکنند.
اکثر افراد میخواهند کار درست را انجام دهند، اما رفتار آنها تحت تأثیر نحوه پاداشدهی قرار میگیرد. بنابراین، بسیار مهم است که حلقههای بازخورد سریع، از مواردی که واقعاً اهمیت دارند ایجاد کنیم:
چگونه مشتریان به آنچه ما میسازیم واکنش نشان میدهند و تاثیر آن بر سازمان ما چیست؟
در چنین رویکردی دیگر نقص هر تیم، عملکرد کل سازمان را پایین میآورد، و افراد را تشویق به همکاری میکند.
مبانیِ تحویلِ مستمر
تحویلِ مستمر بر سه بنیان استوار است: مدیریت جامع پیکربندی، ادغام مستمر و تست مستمر.
مدیریت پیکربندی (Configuration Management)
اتوماسیون نقشِ حیاتی در تضمین انتشارِ (release) مکرر و قابلاعتمادِ نرمافزار ایفا میکند. یکی از اهداف کلیدی این است که فرآیندهای دستی و تکراری مانند ساخت (build)، دیپلویمنت (deployment)، تست رگرسیون و آمادهسازی زیرساخت را خودکار کنیم. برای دستیابی به این هدف، باید هر چیزی که برای انجام این فرآیندها لازم است را تحتِ نسخهگذاری (version control) قراردهیم، از جمله سورسکُد، اسکریپتهای تست و دیپلویمنت، اطلاعاتِ پیکربندیِ زیرساخت و برنامه، و همچنین کتابخانهها و بستههایِ مورد نیاز. همچنین میخواهیم امکان پرسوجوی وضعیت فعلی و تاریخیِ محیطهایمان را بهراحتی فراهم کنیم.
ما دو هدف اصلی داریم:
- تکرارپذیری (Reproducibility): باید بتوانیم هر محیطی را بهصورت کاملاً خودکار آماده کنیم و مطمئن باشیم که هر محیطِ جدیدی که از همان پیکربندی تولید میشود، دقیقاً مشابه قبلی است.
- قابلیتِ ردیابی (Traceability): باید بتوانیم هر محیط را بررسی کرده و بهسرعت و دقت، نسخههای تمام وابستگیهایی را که برای ایجاد آن محیط استفاده شدهاند، مشخص کنیم. همچنین باید بتوانیم نسخههای قبلی یک محیط را مقایسه کرده و تغییرات بین آنها را مشاهده کنیم.
اگر در فهم و درک ۲ هدف بالا ابهام دارید، با مقاله پیش بیایید، با مثالهای عملی و توضیحاتِ در ادامه این ابهام برطرف خواهد شد. ولی بههرحال، این ۲ قابلیت چندین مزیت را برای ما به ارمغان میاورد.
- بازیابی در شرایط بحرانی: در مواقعی که مشکلی در یکی از محیطهایمان پیش میآید، مانند خرابیِ سختافزاری یا نفوذِ امنیتی، باید بتوانیم آن محیط را در زمانی مشخص و بهصورت قطعی بازتولید کنیم تا خدماتمان را بازیابی کنیم.
- قابلیت حسابرسی: برای اثباتِ یکپارچگی فرآیندِ تحویل، باید بتوانیم مسیر بازگشتیِ هر دیپلویمنت را تا اجزای سازندهاش، شامل نسخهها و کامیتها، نشان دهیم. مدیریت پیکربندی جامع، با پایپلاینهای دیپلویمنت که ادغام میشوند، این امکان را فراهم میکند.
- کیفیت بالاتر: فرآیند تحویلِ نرمافزار اغلب به دلیل آمادهسازیِ محیطهای توسعه، تست و عملیاتی با تأخیر مواجه میشود. وقتی این فرآیندها بهطور خودکار و از طریق کنترل نسخه (version control) انجام شوند، میتوانیم سریعتر بازخورد بگیریم و کیفیت را در نرمافزار خود ارتقا دهیم.
- مدیریت ظرفیت: وقتی بخواهیم ظرفیتِ (capacity) محیطهایمان را افزایش دهیم، تواناییِ ایجاد کپیهایی از سرورهای موجود ضروری است. این قابلیت امکان مقیاسپذیری افقیِ سیستمهایِ توزیعشده مبتنی بر ابر (cloud) را فراهم میکند.
- پاسخ به نقصها: وقتی یک نقصِ (defect) بحرانی یا آسیبپذیری در یکی از اجزای سیستم خود پیدا میکنیم، میخواهیم نسخهی جدیدی از نرمافزار را هرچه سریعتر منتشر کنیم. بسیاری از سازمانها برای این نوع تغییرات فرآیندِ اضطراری دارند که با کنار گذاشتن برخی تستها و حسابرسیها سریعتر انجام میشود. این امر در سیستمهای بسیار حیاتی، مشکلساز است. هدف ما این است که بتوانیم از فرآیند انتشار (release) عادی خود برای رفع مشکلات اضطراری استفاده کنیم، که این امر با تحویلِ مستمر و مدیریتِ جامعِ پیکربندی ممکن میشود.
با پیچیدهتر و متنوعتر شدن محیطها، دستیابی به این اهداف دشوارتر میشود. دستیابی به تکرارپذیری و ردیابیِ کامل در سیستمهای پیچیدهی سازمانی تقریباً غیرممکن است. بنابراین، بخش مهمی از مدیریتِ پیکربندی، سادهسازیِ معماری، محیطها و فرآیندها است.
هنگام تلاش برای دستیابی به این مزایا، ابتدا باید اهداف موردنظر را بهصورت قابلاندازهگیری تعریف کنیم. این کار به ما کمک میکند مسیرهایِ ممکن برای رسیدن به هدف را ارزیابی کرده و در صورت نیاز، اگر متوجه شویم روش فعلی بسیار پرهزینه یا زمانبر است، جهت یا اهداف خود را تغییر دهیم.
ادغامِ مستمر (Continuous Integration)
ترکیبِ کار توسعهدهندگان مختلف میتواند بسیار پیچیده باشد. سیستمهای نرمافزاری خودشان نیز پیچیدهاند و یک تغییرِ ساده و ظاهراً مجزا در یک فایل میتواند بهراحتی پیامدهای پیشبینینشدهای داشته باشد که درستی و سلامتِ سیستم را به خطر بیندازد. به همین دلیل، برخی تیمها، توسعهدهندگان را وادار میکنند تا بهطور جداگانه و روی برنچهای مجزا کار کنند تا هم برنچِ اصلی (trunk یا master) پایدار بماند و هم از تداخل کاری میان توسعهدهندگان جلوگیری شود.
با این حال، با گذشت زمان این برنچها از یکدیگر فاصله میگیرند. در حالی که ادغام یک برنچِ مجزا با برنچِ اصلی معمولاً دشوار نیست، وقتی صحبت از ادغام (merge) چندین برنچِ بلندمدت به میان میآید، کار به شدت سخت میشود. این فرایند نیازمندِ بازنگری و اصلاحات زیادی است زیرا فرضیاتِ مغایرِ توسعهدهندگان نمایان شده و باید رفع شوند.
تیمهایی که از برنچهایِ بلندمدت (long-lived) استفاده میکنند، اغلب مجبور به اعمال فریزِ کد (code freeze) یا حتی مراحل جداگانهای برای ادغام و تثبیت کدها میشوند تا این برنچها را پیش از انتشار نهایی یکپارچه کنند. حتی با وجود ابزارهای مدرن، این فرایند همچنان پرهزینه و غیرقابل پیشبینی است. در تیمهایی که تعداد توسعهدهندگان زیاد است، ادغامِ چندین برنچِ مختلف نیازمند چندین دور آزمون رگرسیون (regression testing) و رفع باگ است تا اطمینان حاصل شود که سیستم پس از ادغام بهدرستی کار خواهد کرد. این مشکل با افزایشِ تعدادِ اعضای تیم و عمر برنچها، به شکل تصاعدی حادتر میشود.
یکپارچهسازی مستمر بهمنظور حل این مشکلات ابداع شد. CI از اصول برنامهنویسیِ مفرط (XP یا Extreme Programming) الهام گرفته است، بهویژه این اصل که اگر چیزی دردناک است، باید آن را بیشتر انجام دهیم و این درد را به مراحل اولیه منتقل کنیم. بنابراین، در CI توسعهدهندگان موظف هستند که تمام کارهای خود را بهطور منظم (حداقل روزانه) در برنچِ اصلی (trunk یا main یا master) ادغام کنند. یک مجموعه آزمون خودکار قبل و بعد از ادغام اجرا میشود تا اطمینان حاصل شود که هیچ عقبگردی (regression) در سیستم ایجاد نشده است. اگر این آزمونها شکست بخورند، تیم فوراً کار خود را متوقف کرده و مشکل را حل میکند.
این رویکرد تضمین میکند که نرمافزار همیشه در وضعیت کاری باقی بماند و برنچهایِ توسعهدهندگان از برنچِ اصلی فاصله زیادی نگیرند. مزایای CI بسیار چشمگیر است. تحقیقات نشان میدهد که این روش باعث افزایشِ بهرهوری، پایداریِ بیشتر سیستمها، و کیفیتِ بالاترِ نرمافزار میشود. با این حال، این رویکرد همچنان بهدلیل دو مسئلهی اصلی بحثبرانگیز است.
اول آنکه، یکپارچهسازیِ مستمر نیازمند آن است که توسعهدهندگان ویژگیها (features) یا تغییرات بزرگ را به گامهای کوچکتر و تدریجی تقسیم کنند که بتوان آنها را سریعاً در برنچِ اصلی ادغام کرد. این تغییرِ رویکرد برای توسعهدهندگانی که به این شیوه کار عادت ندارند، یک تغییر اساسی است. همچنین ممکن است تکمیل ویژگیهایِ بزرگ زمان بیشتری ببرد. بطور کلی هدف این نیست که سرعتِ تکمیلِ کار روی یک برنچرا بهتر کنیم. بلکه باید تلاش کنیم تا تغییرات را سریعتر بازبینی، ادغام، آزمایش و منتشر کنیم—فرایندی که با تغییرات کوچک و شاخههای کوتاهمدت، به مراتب سریعتر و کمهزینهتر انجام میشود. کار در گامهای کوچک همچنین به توسعهدهندگان بازخورد مستمر میدهد: بازخوردی از سوی سایر توسعهدهندگان، تستکنندگان، مشتریان، و آزمونهایِ خودکارِ عملکرد و امنیت. این بازخوردها مشکلاتِ احتمالی را سادهتر قابل تشخیص، اولویتبندی و رفع میکنند. در قسمت اصولِ تحویلِ مستمر نیز به این مسئله پرداختیم که کار روی تغییراتِ کوچک (small batches) چه مزایایی دارد.
دوم آنکه، CI نیازمند مجموعهای از unit testهای خودکار است که سریع و جامع باشند. این آزمونها باید به اندازهیِ کافی جامع باشند تا اطمینان بدهند که نرمافزار بهدرستی کار میکند، اما در عین حال باید ظرف چند دقیقه اجرا شوند. اگر اجرای این آزمونها بیش از حد طول بکشد، توسعهدهندگان علاقهای به اجرای مکرر آنها نخواهند داشت و نگهداری از آنها نیز دشوار میشود. ایجاد مجموعههایِ آزمونِ خودکارِ پایدار و قابل نگهداری فرایندی پیچیده است و بهترین روش برای این کار استفاده از توسعهی آزمونمحور (TDD یا Test-Driven Development) است. در TDD توسعهدهندگان ابتدا آزمونهای شکستخورده مینویسند و سپس کدی مینویسند که این آزمونها را پاس کند. این روش مزایای متعددی دارد که مهمترین آن این است که کدی تولید میشود که ماژولار و قابل آزمون است و هزینه نگهداری مجموعه آزمونهای خودکار کاهش مییابد. اما TDD هنوز بهاندازه کافی فراگیر نشده است.
با وجود این چالشها، کمک به تیمهای توسعه نرمافزار برای پیادهسازی CI باید اولویتِ اول هر سازمانی باشد که میخواهد سفر خود بهسوی تحویل مستمر (Continuous Delivery یا CD) را آغاز کند. CI با ایجاد چرخههای بازخورد سریع و اطمینان از اینکه توسعهدهندگان در گامهای کوچک کار میکنند، به تیمها کمک میکند کیفیت را در نرمافزار خود بگنجانند. این امر هزینه توسعه مداوم نرمافزار را کاهش میدهد و در عین حال بهرهوری تیمها و کیفیت کار تولیدی را افزایش میدهد. در صفحهی اول این وبسایت نیز، درخصوص کاهش هزینههای نرمافزار مفصل بحث شده است و به رویکردهای CI و TDD نیز اشاره کردهام.
تست مستمر (Continuous Testing)
کلید دستیابی به کیفیت در نرمافزار، اطمینان از دریافت بازخورد سریع در مورد تأثیر تغییرات است. در گذشته، از بازرسیِ دستیِ کدها و تستِ دستی (که در آن تستکنندگان بر اساس اسناد مشخص، مراحل مختلف سیستم را آزمایش میکردند) به طور گستردهای استفاده میشد تا درستی سیستم را نشان دهند. این نوع تست، معمولاً در مرحلهای پس از «اتمام توسعه» انجام میشد. این استراتژی چندین مشکل دارد:
- تست رگرسیونِ دستی زمانبر و پرهزینه است: این نوع تست یک گلوگاه ایجاد میکند که مانع از انتشارِ مکررِ نرمافزار میشود و بازخورد به توسعهدهندگان را، هفتهها (و گاهی ماهها) پس از نوشتن کد فراهم میکند.
- تستها و بازرسیهای دستی قابلاعتماد نیستند: انسانها به طور ذاتی در انجام وظایف تکراری مانند تستِ رگرسیونِ دستی ضعیف عمل میکنند. همچنین پیشبینیِ تأثیرِ مجموعهای از تغییرات روی یک سیستم پیچیدهی نرمافزاری، از طریق بازرسیِ دستی بسیار دشوار است.
- بهروزرسانی مستندات تست وقتگیر است: در سیستمهایی که با گذر زمان تکامل پیدا میکنند (همانند محصولات و خدمات نرمافزاری مدرن)، باید تلاشِ زیادی صرف بهروزرسانی مستنداتِ تست شود تا همواره دقیق و بهروز باشند.
برای اینکه کیفیت را در نرمافزار نهادینه کنیم، باید رویکردِ متفاوتی اتخاذ کنیم. هدف ما این است که انواعِ مختلف تستها—چه دستی و چه خودکار—را به طور مداوم در طولِ فرآیندِ تحویل اجرا کنیم. انواع تستهایی که باید اجرا شوند، به خوبی در نمودارِ چهار بخشیِ طراحی شده توسط «برایان ماریک» نمایش داده شدهاند.

وقتی یکپارچهسازیِ مستمر و خودکارسازیِ تستها را پیادهسازی کردیم، گام بعدی ایجاد پایپلاینِ دیپلویمنت است که الگویی کلیدی در تحویل مستمر محسوب میشود. در الگوی پایپلاینِ دیپلویمنت، هر تغییری که اعمال میشود، یک فرآیند ساخت (Build) را آغاز میکند که الف) پکیجهایی قابلِ دیپلوی در هر محیط ایجاد میکند. ب) تستهای واحد (Unit Tests) و شاید وظایف دیگری مانند تحلیلِ ایستا (Static Analysis) را اجرا میکند و طی چند دقیقه بازخوردی سریع به توسعهدهندگان ارائه میدهد. پکیجهایی که این مرحله از تستها را با موفقیت پشت سر بگذارند، تحت مجموعهای از تستهای جامعتر، مانند تستهای پذیرش خودکار (Automated Acceptance Tests)، بررسی میشوند.
در نهایت، پکیجهایی که تمام تستهایِ خودکار را با موفقیت پشت سر بگذارند، برای دیپلوی در محیطهای مختلف در دسترس قرار میگیرند. این محیطها ممکن است برای فعالیتهایی مانند تست اکتشافی (exploratory)، تست قابلیتِ استفاده (Usability Testing) و در نهایت انتشار نهایی مورد استفاده قرار گیرند.
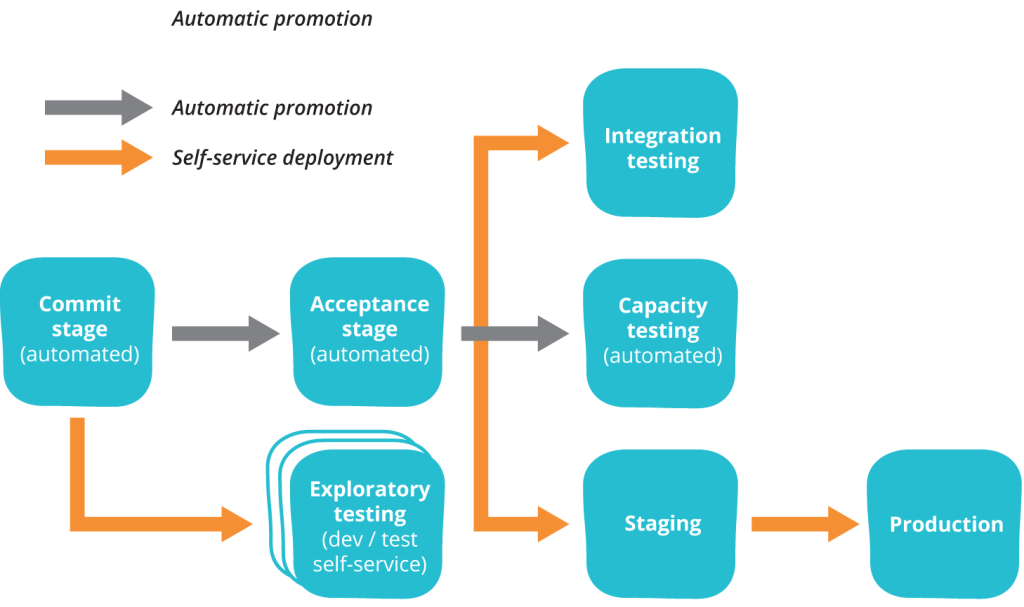
محصولات و خدمات پیچیده ممکن است پایپلاینِ دیپلویمنتِ بسیار پیشرفتهای داشته باشند. اما در سادهترین حالت، یک پایپلاینِ خطی (Linearly Simplified Pipeline) میتواند مشابه تصویر زیر باشد.
در یک پایپلاینِ دیپلویمنت، هر تغییری بهطور مؤثر یک کاندیدای انتشار (release candidate) محسوب میشود. وظیفهی پایپلاینِ دیپلویمنت این است که مشکلاتِ شناختهشده را شناسایی کند. اگر نتوانیم هیچ مشکلی شناسایی کنیم، باید کاملاً احساس اطمینان کنیم که میتوانیم هر پکیجی که از این پایپلاین عبور کرده است را منتشر کنیم. اگر اینگونه نیست یا بعداً اشکالاتی پیدا کنیم، به این معناست که باید پایپلاینِ خود را بهبود دهیم، شاید با اضافه کردن یا بهروزرسانیِ برخی تستها.
هدف ما باید این باشد که مشکلات را در سریعترین زمان ممکن پیدا کنیم و زمانِ بینِ ثبت تغییرات (Check-in) تا انتشار را به حداقل برسانیم. بنابراین، باید فعالیتهای درون پایپلاین بصورت موازی اجرا شوند، نه اینکه مراحل زیادی را بهصورت سریالی انجام دهیم. همچنین، فرآیند بازخوردی نیز وجود دارد: اگر در تستهای اکتشافی (Exploratory Testing) باگهایی پیدا کنیم، باید بهبود تستهای خودکار را مدنظر قرار دهیم. اگر در تستهای پذیرش (Acceptance Tests) نقصی پیدا کنیم، باید بهبود تستهای واحد (Unit Tests) را مدنظر داشته باشیم (بیشتر نقصها باید در مرحلهی تست واحد (unit test) شناسایی شوند).
برای شروع، یک اسکلتِ ابتدایی از پایپلاینِ دیپلویمنت بسازید—یک تست واحد، یک تست پذیرش، یک اسکریپت دیپلویِ خودکار که یک محیط تست اکتشافی را ایجاد کند، و سپس اینها را به هم متصل کنید. سپس با توسعهی محصول یا سرویسِ خود، پوشش تستها را افزایش دهید و پایپلاینِ دیپلویمنت را گسترش دهید.
پیادهسازیِ تحویلِ مستمر
سازمانهایی که تلاش میکنند تحویلِ مستمر را پیادهسازی کنند، معمولاً دو اشتباه رایج مرتکب میشوند. اولین اشتباه این است که تحویلِ مستمر را بهعنوان یک وضعیت نهایی یا هدف اصلی در نظر میگیرند. دومین اشتباه این است که زمان و انرژی زیادی را صرف نگرانی درباره انتخاب ابزارها و محصولات میکنند.
در این بخش، میخواهیم درباره دو مانعِ اصلی و واقعی برای تحویلِ مستمر صحبت کنیم: معماریِ سازمانی و فرهنگِ سازمانی. همچنین میتوانید مجموعهای از الگوهایِ موفق را ببینید که برای افزایش سرعت، پایداری و کیفیت به کار گرفته شدهاند.
معماری
در زمینه معماری سازمانی، معمولاً با ویژگیهای مختلفی مانند دسترسپذیری، امنیت، عملکرد، قابلیت استفاده و غیره سروکار داریم. در تحویل مستمر، دو ویژگی جدید به معماری معرفی میکنیم: قابلیت تست و قابلیت استقرار (دیپلویمنت).
در یک معماریِ قابل تست، نرمافزار به گونهای طراحی میشود که اکثر ایرادات (حداقل در تئوری) توسط توسعهدهندگان و با اجرای تستهای خودکار روی ماشینهای خودشان کشف شود. برای انجام اکثر تستهای پذیرش (acceptance) و رگرسیون، نیازی نیست به محیطهای پیچیده و یکپارچه وابسته باشیم.
در یک معماریِ قابل استقرار، دیپلویِ یک محصول یا سرویسِ خاص میتواند به صورت مستقل و کاملاً خودکار انجام شود، بدون نیاز به هماهنگیهای پیچیده. سیستمهای قابلِ استقرار (deployable) معمولاً میتوانند بدون هیچگونه یا با حداقل زمانِ داونتایم (down time) بهروزرسانی یا پیکربندی شوند.
در صورتی که قابلیت تست و قابلیت استقرار، اولویت نداشته باشند، تستها نیازمند محیطهای پیچیده و یکپارچه خواهند شد و استقرارها به صورت “بیگبنگی” انجام میشوند؛ به این معنا که بسیاری از سرویسها به دلیل وابستگیهای پیچیده باید همزمان منتشر شوند. این استقرارهای بیگبنگی نیازمند هماهنگیِ دقیق بین تیمهای مختلف و فراهم کردن هزارویک شرایط هستند. چنین استقرارهایی معمولاً ساعتها یا حتی روزها زمان میبرند و نیاز به برنامهریزی برای داونتایمهایِ قابل توجه دارند.
طراحی برای قابلیت تست و استقرار از اینجا شروع میشود که محصولات و سرویسهای ما از اجزا یا ماژولهای مستقل و «خوب کپسولهشده» تشکیل شده باشند. در برنامهنویسی شیگرا، چنین سیستمهایی اصولِ طراحیِ SOLID را دنبال میکنند. من در صفحهی اصلی وبسایت در خصوص DDD نیز صحبت کردهام، استفاده از رویکردِ DDD نیز کمک شایانی در تشخیص و کپسوله کردن ماژولها میکند.
یک معماریِ ماژولارِ خوب به گونهای است که بتوان یک جزء یا سرویس را به تنهایی تست کرد یا استقرار داد و وابستگیهای آن را با یک جایگزینِ تست مناسب، مانند استاب (stub) یا ماک (mock)، جایگزین کرد. هر جزء یا سرویس باید بتواند به صورت کاملاً خودکار روی ماشینِ توسعهدهنده، محیطهایِ تست یا در عملیاتی مستقر شود.
برای تسهیلِ استقرارِ مستقلِ اجزا، باید روی ایجاد APIهای نسخهدار که قابلیت سازگاری با نسخههای قبلی را دارند (backwards compatibility)، سرمایهگذاری کنیم. تضمینِ سازگاری با نسخههای قبلیِ APIها، پیچیدگیِ سیستم را افزایش میدهد، اما انعطافی که در تسهیلِ استقرار به دست میآوریم، این هزینه را چندین برابر جبران خواهد کرد.
هر معماری سرویسمحوری (service oriented) باید این ویژگیها را داشته باشد، اما متأسفانه بسیاری از آنها ندارند. با این حال، جنبش میکروسرویسها به طور خاص این ویژگیهایِ معماری را در اولویت قرار داده است.
معماریِ تکاملی (Evolutionary)
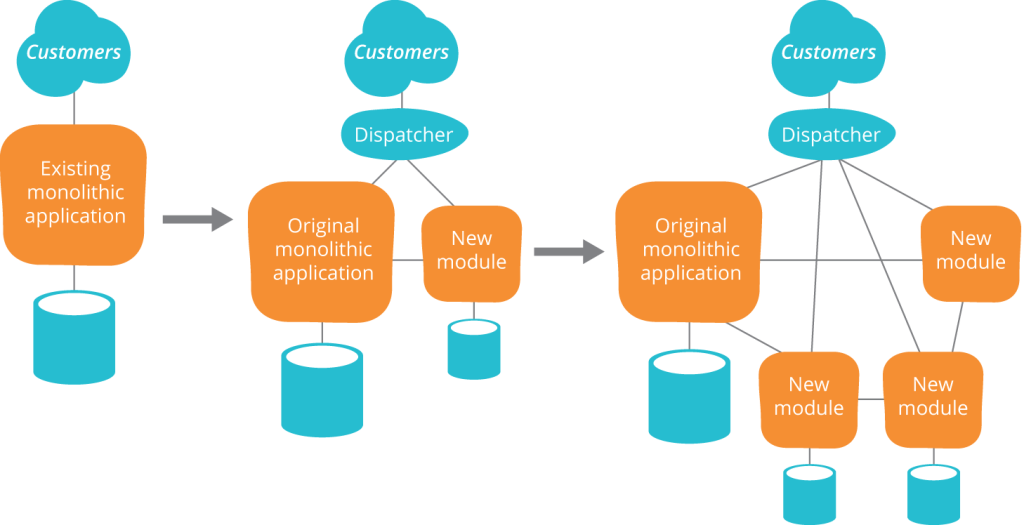
بسیاری از سازمانها در دنیایی زندگی میکنند که خدماتِ آنها به سختی قابل تست و استقرار هستند. به جای بازمعماری یا بازطراحیِ (re-architecting) کامل همهچیز، ما یک رویکرد تدریجی برای بهبودِ طراحیِ سیستمِ سازمانی را توصیه میکنیم که گاهی اوقات به آن معماری تکاملی گفته میشود. در پارادایمِ معماری تکاملی، میپذیریم که محصولات و خدماتِ موفق در طولِ چرخه عمرِ خود به دلیل تغییرِ نیازها، نیازمند بازطراحی خواهند بود.
یکی از الگوهایِ بسیار مفید در این زمینه، برنامه خفهکننده (Strangler Application) است. در این الگو، بهتدریج یک معماریِ مونولوتیک را با معماریِ سرویسمحور، جایگزین میکنیم، به این صورت که کارهای جدید را بر اساسِ اصولِ معماریِ مبتنی بر سرویس (service oriented) انجام میدهیم. با گذشتِ زمان، عملکردهای بیشتری را از معماری مونولوتیک به معماری جدید مهاجرت خواهیم داد، و سیستم قدیمی که در حال جایگزینی است، به تدریج “خفه” میشود.
فرهنگ
ادگار شاین، نویسندهی کتابِ راهنمای بقا در فرهنگ سازمانی، فرهنگ را به این صورت تعریف میکند:
«فرهنگ الگویی از فرضیاتِ نانوشته و مشترک است، که یک گروه در فرآیندِ حلِ مشکلاتِ تطبیق با محیطِ بیرونی (external adaptation) و یکپارچگی داخلی (internal integration) آموخته است. این الگوها بهقدری موفق بودهاند که بهعنوان الگوهای معتبر شناخته شدهاند و به اعضایِ جدید بهعنوان شیوهی درست درک، تفکر و احساس آموزش داده میشوند»
فرهنگ ناملموس است و تغییر آن دشوار، اما قابل اندازهگیری بوده و اهمیت حیاتی برای موفقیتِ شرکت دارد. پژوهشی که در گزارش وضعیت DevOps سال ۲۰۱۴ منتشر شده، نشان میدهد که در حوزه فناوری اطلاعات، رضایت شغلی بزرگترین عامل پیشبینیکننده سودآوری، سهم بازار و بهرهوری است. (به مقالهی تجربهی توسعهدهندگان مراجعه کنید) از سوی دیگر، بزرگترین عامل پیشبینیکنندهیِ رضایت شغلی، نحوهیِ پردازشِ اطلاعات توسط سازمانها است، که طبق مدلی که توسط جامعهشناس ران وستروم ارائه شده، ارزیابی میشود. پیشتر من مقالهی مفصلی در این خصوص نوشتهام.
تحقیقاتِ وستروم بر اهمیت ایجاد فرهنگی تأکید میکند که در آن از ایدههای جدید استقبال میشود، افراد از سراسر سازمان برای دستیابی به اهداف مشترک همکاری میکنند، افراد آموزش میبینند که خبرهای بد را مطرح کنند تا بتوان بر اساس آنها اقدام کرد، و شکستها و حوادث به عنوان فرصتهایی برای یادگیری و بهبود تلقی میشوند، نه جستوجوی مقصر.
جنبش DevOps همیشه بر اهمیت اصلی فرهنگ تأکید کرده است، به ویژه بر همکاری مؤثر بین تیمهای توسعه و تیمهای عملیات. تحقیقات نشان داده است که رابطه برد-برد بین تیمهای توسعه و عملیات، پیشبینیکنندهی مهمی برای عملکرد فناوری اطلاعات است. متخصصان جنبش DevOps از ابزارهای مختلفی برای کمک به سازمانها در پردازش بهتر اطلاعات استفاده کردهاند، از جمله چتاپس، گزارشهای Postmortem بدون سرزنش، و مدیریت جامع پیکربندی.
در واقع، شرکتهای با عملکرد بالا منتظر وقوع مشکلات نمیمانند تا از آنها درس بگیرند؛ بلکه به طور منظم حوادث (کنترلشده) ایجاد میکنند تا سریعتر از رقبا یاد بگیرند. در خصوص مهندسی آشفتگی در صفحهی نخستِ وبسایت صحبت شده است. نتفلیکس این مفهوم را با Simian Army به سطح جدیدی برده است؛ مجموعهای از ابزارها که به طور مداوم زیرساختهای این شرکت را مختل میکنند تا مقاومت سیستمها را پیوسته آزمایش کنند.
تمِ مشترکی که در سازمانهای با عملکرد بالا مشاهده میشود این است که آنها همیشه در تلاش برای بهتر شدن هستند. به جای اینکه منتظر تغییر محیط اطراف باشند یا خود را با دیگران مقایسه کنند، خود را به عنوان استانداردی برای پیشی گرفتن در نظر میگیرند.
الگوها
لیندا رایزینگ، الگو را اینگونه تعریف میکند: «یک استراتژیِ نامگذاریشده، برای حل یک مشکل تکرارشونده.» مفهومِ الگوها از کارهای معمار کریستوفر الکساندر نشأت گرفته است. او بیان میکند: «هر الگو مشکلی را توصیف میکند که بارها و بارها در محیط ما رخ میدهد و سپس راهحلِ آن مشکل را به شکلی شرح میدهد که میتوانید این راهحل را میلیونها بار استفاده کنید، بدون اینکه دقیقاً به یک شکل انجام شود.»
الگویِ پایپلاینِ دیپلویمنت (The Deployment Pipeline)
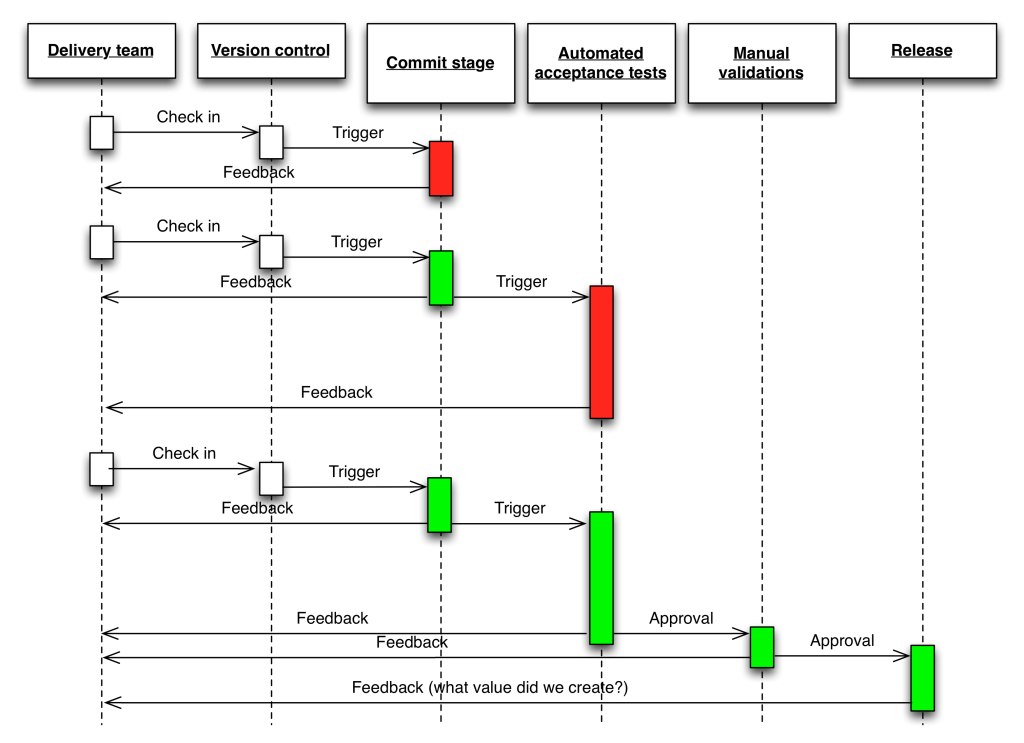
الگوی کلیدی معرفیشده در تحویل مستمر (Continuous Delivery) پایپلاینِ استقرار یا دیپلویمنت است. این الگو از چندین پروژه شرکت ThoughtWorks به وجود آمد، جایی که با فرآیندهای دستیِ پیچیده، شکننده و طاقتفرسا برای آمادهسازی محیطهای آزمایشی و عملیاتی و همچنین استقرار نسخهها در آنها دستوپنجه نرم میکردند. ما پیشتر تلاش کرده بودیم بخش قابلتوجهی از تستهای رگرسیون و پذیرش را خودکار کنیم، اما همچنان هفتهها طول میکشید تا نسخهها به محیطهای یکپارچه برای تست کامل رگرسیون برسند، و اولین دیپلوی ما در محیط عملیاتی یک آخر هفتهیِ کامل زمان برد.
ما میخواستیم فرآیند انتقال تغییرات از کنترل نسخه به محیط عملیاتی را مکانیزه کنیم. هدف ما این بود که دیپلوی در هر محیطی به فرآیندی کاملاً خودکار و اسکریپتشده تبدیل شود که بتوان آن را در عرض چند دقیقه و در هر زمان انجام داد (در پروژه اولیه این زمان را به کمتر از یک ساعت کاهش دادیم، که برای یک سیستم سازمانی در سال ۲۰۰۵ دستاورد بزرگی بود). همچنین میخواستیم محیطهای آزمایش و عملیات را صرفاً از طریق فایلهای پیکربندی ذخیرهشده در کنترل نسخه کانفیگ کنیم. ابزارهایی که برای انجام این کار استفاده کردیم (معمولاً به شکل مجموعهای از اسکریپتها در Bash یا Ruby) به نام پایپلاینِ دیپلویمنت شناخته شدند، که دن نورث، کریس رید و جزهامبل در مقالهای که در کنفرانس Agile 2006 ارائه کردند، آن را توصیف کردند.
در الگوی پایپلاینِ استقرار، هر تغییری در کنترل نسخه یک فرآیند را (معمولاً در یک سرور CI) آغاز میکند که در نهایت پکیجهای قابل استقرار ایجاد کرده و تستهای واحد (unit tests) خودکار و سایر اعتبارسنجیها مانند تحلیل استاتیکِ کد را اجرا میکند. این مرحله اولیه بهینهسازی شده است تا تنها چند دقیقه طول بکشد. اگر این مرحله اولیه شکست بخورد، مشکل باید فوراً برطرف شود—هیچکس نباید روی مرحلهای که شکست خورده است، کار بیشتری ثبت کند. هر مرحله موفق در این پایپلاین، مرحله بعدی را آغاز میکند که ممکن است شامل مجموعهای جامعتر از تستهای خودکار باشد. نسخههایی از نرمافزار که تمام تستهای خودکار را با موفقیت پشت سر میگذارند، میتوانند بر اساس تقاضا به مراحل بعدی مانند تست اکتشافی، تست عملکرد، محیط آزمایشی و عملیاتی مستقر شوند. این موضوع در شکل زیر تصویر شده است.